语音识别技术,简言之,就是将说话声转化为文字或命令的过程。现在,这项技术已在众多行业中得到广泛应用,极大地方便了我们的日常生活和职业活动。
语音识别的原理
语音识别的第一步是音频的收集。这一步骤就好比开启了一扇通向声音世界的门户,捕捉到人类产生的声音信号。以手机中的语音助手为例,麦克风负责捕捉声音。在技术方面,语音识别依赖于声学模型和语言模型。声学模型负责分析声音的声学属性,如频率、强度等,这些是识别语音的基础特征。而语言模型则依据特定的语法规则和语料库,从众多可能的语义中筛选出最合适的解释。
在智能设备中的应用
在日常生活中,智能音箱普遍运用了语音识别技术。用户只需开口,就能控制它播放音乐、查询天气等。智能手机也得益于语音识别,我们能够通过语音输入文字,大大提升了输入效率。在驾驶过程中,语音识别功能允许司机在双手不便操作手机时,依然能够接听电话、获取导航信息,从而增强了驾驶的安全性。
在特殊场景中的助力
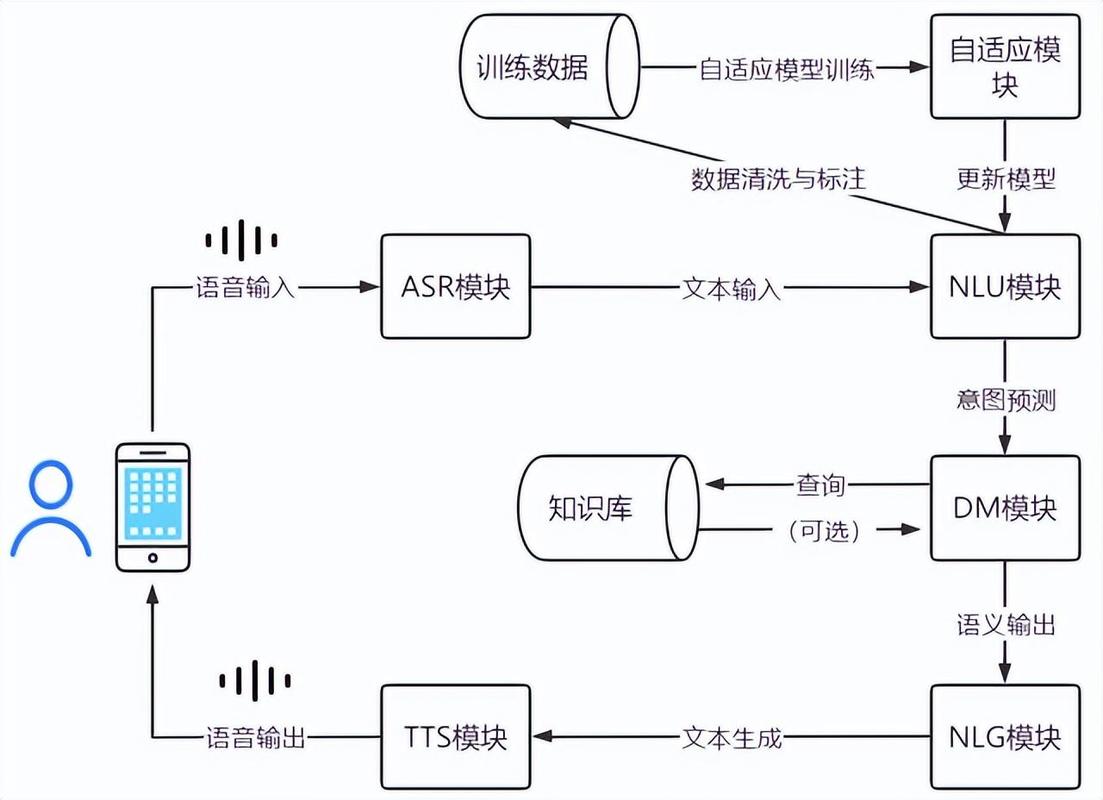
在医疗行业,语音识别技术帮助医生减少了书写病历的复杂耗时。医生只需口头描述,系统便能自动将其转化为文字病历。对于残障人士,尤其是视力受损者来说,语音识别是他们与数字世界沟通的关键途径。举例来说,借助语音识别软件,视障人士同样可以轻松使用电脑,浏览网络信息。
语音识别技术的发展瓶颈与突破
语音识别技术已取得显著进展,然而仍存在不少挑战。首先,噪音干扰严重影响了识别的准确性,尤其在嘈杂环境中,准确率会显著降低。其次,口音和方言的丰富性也增加了识别难度。为了克服这些难题,科研人员正持续改进算法,并扩大方言语料库的规模。
你是否有过这样的经历,方言在语音识别时显得有些尴尬?欢迎在评论区交流心得,觉得内容不错的话,不妨点赞并转发一下。
发表回复